Disclosure: I use generative AI when specifically writing about my own experiences, ideas, stories, concepts, tools, tool documentation or research. My tool of choice for this process is Google Gemini Pro 2.5 Deep Research (and ChatGPT 5 for image generation). I have over 20 years writing about accessible website development and SEO (search engine optimisation). This assistance helps ensure our customers have clarity on everything we are involved with and what we stand for. It also ensures that when customers use Google Search to ask a question about Hobo Web software, the answer is always available to them, and it is as accurate and up-to-date as possible. All content was conceived, edited, and verified as correct by me (and is under constant development). See my AI policy.
Disclaimer: This is not official. It is theory. Any article (like this) dealing with the Google Content Data Warehouse leak requires a lot of logical inference when putting together the framework for SEOs, as I have done with this article. I urge you to double-check my work and use critical thinking when applying anything for the leaks to your site. My aim with these articles is essentially to confirm that Google does, as it claims, try to identify trusted sites to rank in its index. The aim is to irrefutably confirm white hat SEO has purpose in 2025 – and that purpose is to build high-quality websites. Feedback and corrections welcome.
When I first started in a Glasgow advertising agency, back in 1999, the internet was still the wild west, but the rules of the game were ancient.
The office was run by old-school ad men, guys who had spent decades in the trenches of print. They lived and breathed the wisdom of legends like David Ogilvy, and they quoted him like scripture.
For them, the single most important element of any campaign was the headline. For us, it is the Page Title.
As Ogilvy himself famously said, “On the average, five times as many people read the headline as read the body copy. When you have written your headline, you have spent eighty cents out of your dollar.”

I started my career in that world, working in the studio with Quark Express and Photoshop, laying out print ads where the headline was king.
He drove the point home, stating, “It follows that, if you don’t sell the product in your headline, you have wasted 80 percent of your money.”
I watched firsthand as the industry began its slow, awkward pivot from print to the web. That powerful principle didn’t just migrate online; it became supercharged with a new, brutal reality.
In the print world, a weak headline meant you wasted your investment.
On the modern Search Engine Results Page (SERP), a weak title tag – the digital successor to the headline in Google Search Results – means you don’t even get to make an investment.
Without clicks, your page becomes invisible.
The title tag isn’t just competing for attention; it’s competing for its very existence. A title that fails doesn’t just yield a poor return; it yields no return at all.
The Dual Mandate: Serving Two Masters
What I quickly learned, especially after I convinced the agency to let me start building websites for our clients, is that this single line of text has an immense, often conflicting, responsibility: it must serve two masters at once.
First, for the human user, your title tag is your ad. It’s the pitch, the promise, the one chance you get to persuade a real person to choose your link over a dozen others. It has to be compelling and persuasive.
This is the art of the title tag, the part that the old ad guys would have understood perfectly.
Second, for the search engine, the title tag is a cold, hard relevance signal.
It’s a piece of data that has to be structured with technical precision. The crawler doesn’t care about wit; it cares about keywords, structure, and semantics.
This is the science of the title tag. My entire career since leaving that agency to start Hobo Web has been about mastering the balance between these two mandates, fitting both the art of persuasion and the science of relevance into one severely constrained string of text.
This article weaves together a narrative from a diverse set of sources, including Google Search Essentials (I still refer to them as webmaster guidelines), Google Quality Rater Guidelines, and the once-in-a-lifetime Google Content Warehouse data leak.
Section 2: The Promise of the Click: Crafting Titles for Human Psychology
Everything I learned from those old ad guys, and everything that has been proven by data over the last 25 years as Google got better and better at identifying quality, starts with one simple idea: before a title can satisfy an algorithm, it must first appeal to a person.
The foundation of this was articulated perfectly by Ogilvy, whose research was unequivocal: “Headlines that promise a benefit sell more than those that don’t.”
This isn’t just a marketing theory; it’s the core of how search works.
As Google states in its own documentation, “Title links are critical to giving users a quick insight into the content of a result and why it’s relevant to their query. It’s often the primary piece of information people use to decide which result to click, so it’s important to use high-quality title text on your web pages.”
A user’s search query is always an unspoken question: “What’s in it for me?”
A title that just describes something – “Our New Accounting Software” – is dead on arrival.
It doesn’t answer the question.
But a title built on a benefit – “Save 10 Hours a Week with Our Accounting Software” – speaks directly to the user’s need. It transforms a label into a solution.
Proven Formulas for Engagement: Ogilvy’s Toolkit for the SERP
The core principle is the promise of a benefit, but the old ad-world toolkit gave us proven formulas that I still use every day.
First is the power of news. As Ogilvy explained, “Time after time, we have found that it pays to inject genuine news into headlines.”
This works because “The consumer is always on the lookout for new products, or new improvements in an old product, or new ways to use an old product.” On the web, this translates to signalling freshness with dates (“for 2024”), updates (“New Algorithm”), or framing content as definitive (“The Ultimate Guide” or “The Definitive Guide”).
Second is the appeal of specificity. Ogilvy observed that headlines with numbers are consistently high performers.
Numbers stand out visually, but more importantly, they promise a structured, scannable, and easily digestible format. “15 Ways to Improve Your Writing” feels more actionable and less intimidating than a vague promise to teach someone “How to Improve Your Writing.”
Third is the technique of engaging curiosity. A question can be incredibly powerful if it mirrors the user’s own internal monologue. A title like “Is SEO worth the investment in 2025?” creates an “open loop” that compels a click to find the answer.
Fourth is the importance of targeting your audience directly. “When you advertise a product which is consumed only by a special group, it pays to ‘flag’ that group in your headline—MOTHERS, BED-WETTERS, GOING TO EUROPE?”
This tactic is perfect for SEO.
Similarly, for local businesses, “In local advertising, it pays to include the name of the city in your headline.”
A title like “Emergency Plumbing Repair in Brooklyn” signals immediate local relevance.
The Power of Simplicity and the Challenge of Compression
Underpinning all of this is a foundational rule of clarity. Ogilvy warned, “Your headline should telegraph what you want to say-in simple language,” because “Readers do not stop to decipher the meaning of obscure headlines.”
This principle is even more critical on the SERP, where I have fractions of a second to make my case. This isn’t just an old-school advertising tip; it’s a core tenet of user-focused writing that Google itself champions. In its own developer style guide, Google states, “Punctuation can be a sign that your heading is too complicated. Consider rewriting.”
The biggest challenge I faced moving from the print world to digital was compression. In print, longer headlines were often better.
Ogilvy’s research found that “headlines of ten words or longer sold more goods than short headlines” and that “In mail-order advertising, headlines between six and twelve words get the most coupon returns.” He concluded, “On the average, long headlines sell more merchandise than short ones-headlines like our ‘At 60 miles an hour, the loudest noise in this new Rolls-Royce comes from the electric clock’.”
You simply can’t do that in a 600-pixel space.
This is why I learned that the title tag can’t work alone. It has to be part of a “creative unit” with the meta description. The title makes the bold, compressed promise, and the description provides the context and proof.
Table 1: Translating Ogilvy’s Advertising Principles into Modern SEO Tactics
| David Ogilvy’s Principle | Modern Title Tag Application (Example) |
| “Promise a benefit.” | Before: “Our New Accounting Software” After: “Save 10 Hours a Week with Our Accounting Software” |
| “Inject news.” | Before: “Guide to SEO” After: “The Ultimate SEO Guide for 2024’s Algorithm Updates” |
| “Include numbers.” | Before: “Ways to Improve Your Writing” After: “15 Actionable Ways to Instantly Improve Your Writing” |
| “Ask a question.” | Before: “The Cost of Solar Panels” After: “Are Solar Panels Worth the Investment in 2024?” |
Section 3: The Technical Blueprint: Engineering Titles for Search Engines
While a psychologically compelling title is necessary to win the click, it is technical precision that earns the right to compete for it.
As I moved from print layouts to building websites, I quickly learned that persuasion alone wasn’t enough.
You have to master the technical side to even get in the game.
The first rule, straight from Google, is to “Make sure every page on your site has a title specified in the <title> element.”
From there, it’s about quality. Google’s advice is to “Write descriptive and concise text for your <title> elements. Avoid vague descriptors like ‘Home’ for your home page, or ‘Profile’ for a specific person’s profile.”
Keyword Architecture: The Science of Relevance Signalling
The most fundamental technical aspect is keyword architecture.
In my experience, search engines still place disproportionate weight on the terms that appear at the beginning of the title. I always “front-load” my most important target keyword. It’s the clearest and fastest signal I can send to a crawler about the page’s core topic.
However, this must be done with care. Google explicitly warns to “Avoid keyword stuffing.”
Their documentation clarifies: “It’s sometimes helpful to have a few descriptive terms in the <title> element, but there’s no reason to have the same words or phrases appear multiple times… this kind of keyword stuffing can make your results look spammy to Google and to users.”
The Physics of the SERP: Mastering Pixel Width and Character Limits
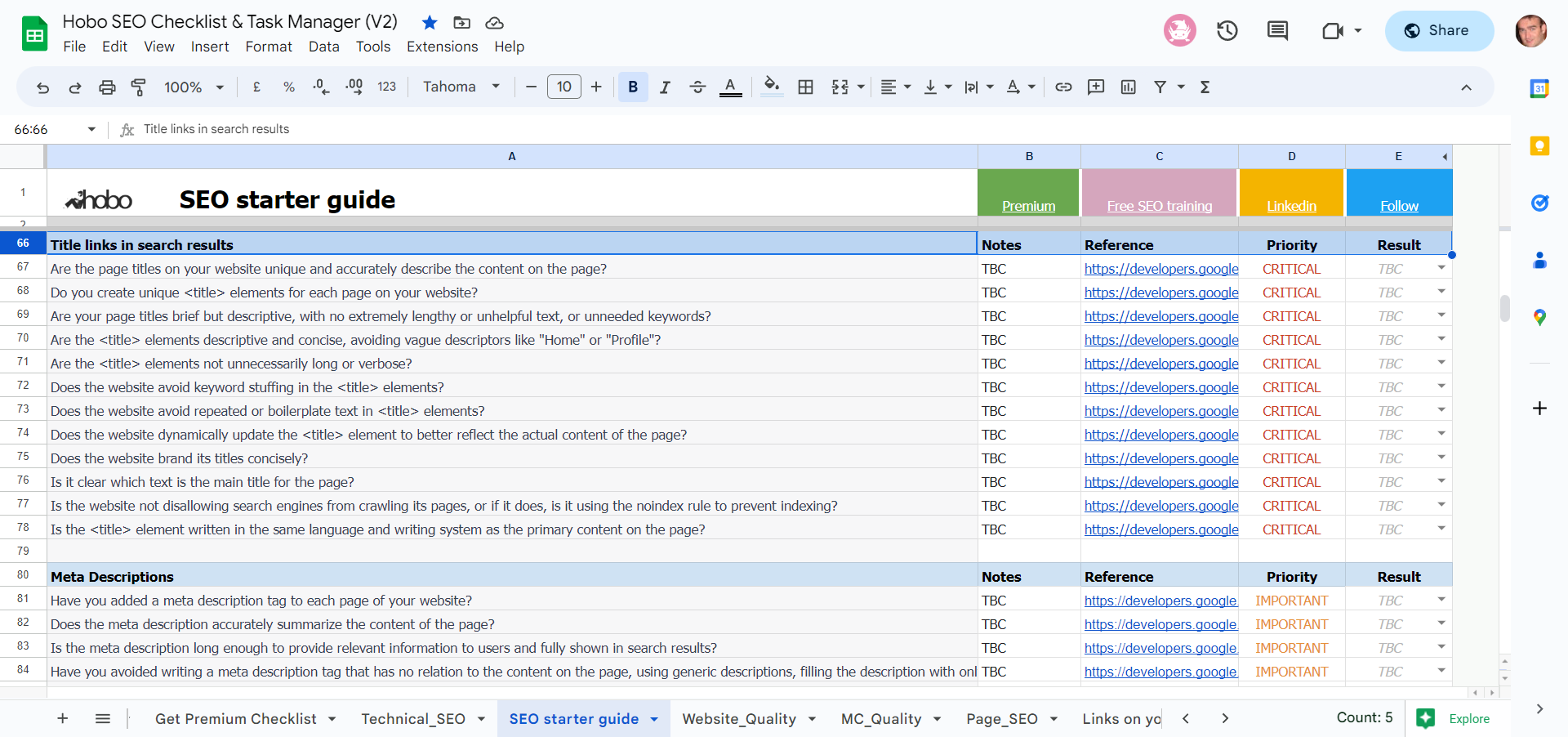
One of the biggest mistakes I see people make is relying on character counts. The real constraint is pixel width. Google gives you about 600 pixels on a desktop SERP.
A ‘W’ takes up a lot more space than an ‘i’. A title that gets cut off with an ellipsis (“…”) is a failed title.
It can hide your keyword or your core benefit and kill your click-through rate (CTR). Google’s advice is to “avoid unnecessarily long or verbose text in your <title> elements.” I never guess; I always use a pixel-width checker tool to see exactly how my title will render.
Structure and Hierarchy: Following the Blueprint
A title tag doesn’t exist in a vacuum; it’s the top of a structural pyramid
A critical part of my process is ensuring every page is unique and avoids lazy repetition.
Google warns to “Avoid repeated or boilerplate text in <title> elements,” explaining that “It’s important to have distinct text that describes the content of the page in the <title> element for each page on your site.”
This structure extends to the page itself. The main on-page title is a huge signal. Google advises webmasters to “Make it clear which text is the main title for the page,” and recommends you “consider ensuring that your main title is distinctive from other text on a page and stands out as being the most prominent on the page (for example, using a larger font, putting the title text in the first visible <h1> element on the page, etc).”
A clean, logical structure sends a powerful signal of quality and coherence.
Strategic Branding: The Anchor in Your Title
Including a brand name is a strategic decision. Back at the agency, we learned this from Ogilvy himself: “That is why most Ogilvy & Mather headlines include the brand name and the promise.” Google agrees, with a caveat.
Their advice is to “Brand your titles concisely.”
They suggest that for internal pages, you should “consider including just your site name at the beginning or end of each <title> element, separated from the rest of the text with a delimiter such as a hyphen, colon, or pipe.”
This isn’t just branding; it’s a calculated move to add a layer of algorithmic defence and trust to your title.
Section 4: Advanced Mechanics and Algorithmic Nuances
After more than two decades of doing this, I’ve learned that optimising a title tag goes beyond the basics. It’s about understanding the complex, sometimes unpredictable, behaviour of the algorithm itself.
- Title Tag Relevance (
titlematchScore): The documentation confirms the existence of atitlematchScore, which values how well the page title matches the user’s query. This is further supported by aBadTitleInfoflag, suggesting that Google’s systems actively identify and penalise poorly constructed titles. Further attributes likeoriginalTitleHardTokenCountandtitleHardTokenCountWithoutStopwordsshow a deep level of title analysis, counting the number of words (tokens) with and without common stopwords. This serves as direct evidence for the continued importance of precise and relevant keyword targeting within the<title>tag.
Decoding and Mitigating Google’s Rewrites
Google rewriting titles is a constant challenge, but it’s not random. As Google explains, the process “is completely automated and takes into account both the content of a page and references to it that appear on the web. The goal of the title link is to best represent and describe each result.”
When my specified <title> tag isn’t used, it’s because the system is pulling from other sources to create what it believes is a better title. Google is transparent about these sources, which include:
- “Content in <title> elements”
- “Main visual title shown on the page”
- “Heading elements, such as <h1> elements”
- “Other content that’s large and prominent through the use of style treatments”
- “Text within links that point to the page”
Often, a rewrite is triggered because Google has detected a problem.
Common issues they identify include “Inaccurate <title> elements” that don’t reflect the page’s content, “Obsolete <title> elements” with outdated information (like a wrong year), or “Micro-boilerplate text” where titles are too similar across multiple pages.
While I can’t prevent all rewrites, my most powerful strategy is to create a strong, coherent relationship between the <title> tag and the <h1> heading. By making the <h1> a compelling alternative, I give Google a clear, preferred option if it decides a rewrite is necessary.
Empirical Validation: A/B Testing and Measuring Title Tag Efficacy

Ultimately, every strategy is just a hypothesis until I test it.
I use A/B testing to move from best practices to proven results. The method is simple: I identify a group of pages, change only the title tag for the test group, and measure the impact on click-through rate (CTR) in Google Search Console.
However, the reality of Google’s rewrites means we don’t have full control.
A rewrite is essentially Google conducting its own involuntary A/B test on my page. It’s the algorithm saying, “Based on the data, I think this other title will perform better.”
This reframes my entire strategy. My goal isn’t just to optimise the <title> tag in isolation.
It’s to create a “constellation of signals” – the <title>, the <h1>, the URL, the intro paragraph – that are so thematically coherent that they leave no room for algorithmic ambiguity.
My job as an SEO is to orchestrate all these elements so tightly that any potential rewrite is guided toward a predictable and favourable outcome.
The Bottom Line Up Front: Key Takeaways for the Modern SEO
For those who need the bottom line up front, here are the most critical takeaways from the Google leak and my 25 years of experience, distilled into a simple guide. These findings are not independent points; they describe a single, interconnected, self-correcting system designed to find the best possible title for the user.
Key Findings: What Has Changed?
- Your <title> Tag Is Just One of Many Candidates: Google doesn’t just use the HTML <title> tag you write. It creates a “pool” of potential titles for your page by also looking at your main headings (<h1>), the anchor text of links pointing to your page, and other prominent text. These candidates then compete against each other. This happens because Google cannot inherently trust that a publisher’s chosen title is the best one for the user.
- User Clicks Are a Powerful Ranking Factor: This is the biggest confirmation from the leak. A system called NavBoost analyses how users interact with your title in the search results. Titles that get “good clicks” (where a user clicks and stays on the page) are rewarded. Titles that get “bad clicks” (where a user clicks and immediately returns to the search results) are penalised. Your title’s most important job is to earn the right click. NavBoost acts as the ultimate arbiter, judging which candidate from the pool best satisfies users.
- Google Actively Scores and Penalises Bad Titles: An internal system codenamed “Goldmine” scores every title candidate. The leak confirms specific metrics like titlematchScore (how well the title matches the query) and a BadTitleInfo flag, which actively identifies and penalises poorly constructed titles like those that are spammy or misleading. This system acts as a pre-filter, removing objectively terrible candidates before they are even tested with users.
- Google Rewrites Most Titles: It is now the norm, not the exception, for Google to change your title. A system called SnippetBrain will rewrite your title if it believes it can create a version that better serves the user. This happens over 76% of the time and is the logical outcome of this entire system, where user data consistently proves that an alternative candidate (like the <h1>) performs better than the publisher’s provided <title>.
Key Strategy Steps: What Should You Do Now?
- Write for Humans, Not Just Bots: Your number one job is to set accurate expectations for the user. Your title must make a clear and honest promise about the content on the page. This is how you earn “good clicks” and send positive signals to the NavBoost system. Avoid “clickbait” at all costs.
- Align Your Primary On-Page Signals: The best way to influence the title Google chooses is to be consistent. Make sure your HTML <title> tag and your main on-page headline (<h1>) send the same clear message about your page’s topic.
- Lead with Your Primary Keyword (Naturally): Place your most important keyword phrase at or near the beginning of your title. This helps both users and Google quickly identify the page’s topic. However, it must read naturally. Don’t force it.
- Follow the Foundational Rules:
- Be Unique: Every page on your site must have a unique title.
- Avoid Keyword Stuffing: Repeating keywords is a negative signal that can get your title penalised.
- Mind the Length: Keep titles around 50-60 characters (approx. 600 pixels wide) to prevent them from being cut off (“truncated”) in search results, which is a direct penalty signal.
- Treat Your Whole Page as an Optimisation Opportunity: Since Google can generate titles from your headings and internal links, make sure they are also descriptive and relevant. Your internal link anchor text should accurately describe the page it’s linking to.
5. First Principles: The Foundational Role of the Title Element
Before delving into advanced strategy, it is essential to establish a firm foundation. The title tag, despite its apparent simplicity, is a cornerstone of on-page search engine optimisation.
Defining the Element: Its Place in HTML and the SERP
At its most fundamental level, the title tag is an element in HTML that defines the purpose of a web page in a concise, relevant sentence. Its syntax is straightforward and must be placed within the <head> section of the HTML document:
<head><title>Your Page Title</title></head>
As Google stated clearly back in 2020, a title tag’s function is foundational:
“A <title> tag tells both users and search engines what the topic of a particular page is. The <title> tag should be placed within the <head> element of the HTML document. You should create a unique title for each page on your site.”
This simple definition, echoed by the W3C’s guidance that a title “defines in a simple phrase the purpose of the document,” is the starting point for a much deeper strategic function.
This single line of code specifies the text that appears in the title bar of a web browser, provides the default text when a page is bookmarked, and, most critically, provides the main clickable headline for a search result on a search engine results page (SERP).
Title Tag vs. H1 Tag: Clarifying the Critical Distinction
A frequent point of confusion is the distinction between the <title> tag and the <h1> tag.
While they often contain similar wording, their roles are different, and this difference is the primary source of the conflict that Google’s title selection engine is designed to resolve.
- The <title> tag carries the most weight, so it is important to get it correct.
- The <title> tag is the crown of a web page, but it is also an off-page, external signal. Its primary audience is the user on the SERP and the search engine’s crawler. It makes a promise to a potential visitor.
- The <h1> tag is the main on-page headline. Its primary audience is the user who has already clicked through to the page. It is the first thing a user sees to verify the promise made by the title.
A significant mismatch between the promise made by the <title> tag and the reality delivered by the <h1> creates a “signal conflict” that can lead to user dissatisfaction and a quick return to the search results.
As we will explore, internal Google systems are designed to measure this exact user behaviour.
By treating the <h1> as a primary replacement candidate for the <title>, Google’s system is essentially pre-emptively solving this conflict.
It’s choosing the signal it believes will lead to the least amount of “pogo-sticking” (bad clicks).
Therefore, aligning them is not just about consistency; it’s about removing ambiguity and giving Google no reason to override your choice.
The “Meta Title” Misnomer: A Point of Technical Clarity
It is also important to clarify a common misnomer: the “meta title.”
While many SEOs and marketing platforms use this term, it is technically incorrect. The title is a standalone HTML element (<title>), not a meta tag (<meta>).
This distinction is important because it underscores the title’s unique and direct role in defining the document for browsers and search engines, separate from other metadata like the meta description.
6. Under the Hood: Deconstructing Google’s Title Selection Engine
The Google leak reveals that the title displayed on the SERP is the winner of a sophisticated, multi-stage competition. This evaluation process can be best understood as a hiring process for the most critical role on the SERP: your page’s advertisement.
The Title Generation Pipeline: From a Single Tag to a Candidate Pool
The process begins with sourcing candidates. Instead of relying on a single application – the HTML <title> tag – the system gathers a pool of candidates from multiple sources to ensure it has the best options.
The QualityPreviewRanklabTitle module within the leak deconstructs this pipeline.
The pipeline starts with sourceTitleTag, the candidate from the HTML <title> element we explicitly declare.
It’s the foundational candidate, but its selection is never guaranteed.
Next, the system extracts candidates from the page’s structure, flagged by sourceHeadingTag (from elements like <h1> and <h2>). A separate, more specific goldmineHeaderIsH1 feature confirms that the primary <h1> tag is given special weight.
The system also pulls from the link graph. The sourceOnsiteAnchor and sourceOffdomainAnchor attributes confirm that both internal and external link anchor text are used as title candidates. This means the consensus of how your own site and other sites describe your page can directly influence its title.
Finally, a fallback sourceGeneratedTitle is used when all publisher-influenced signals are deemed low-quality.
This multi-source process creates a diverse pool of title candidates, ready for evaluation.
The Goldmine Scoring System: Quantifying Title Quality
Once the candidates are gathered, they undergo an initial screening.
This is handled by an internal system codenamed “Goldmine,” which my analysis connects to a process called AlternativeTitlesAnnotator.
This engine turns a title’s text into a quantitative score of its quality.
The system is component-based, breaking down “title quality” into measurable factors, each represented by a goldmine*Factor attribute.
For example, goldmineTitleTagFactor assesses the quality of the <title> tag source, while goldmineBodyFactor measures the semantic relationship between the title and the page’s main content.
These factors are aggregated into a goldminePageScore, a baseline quality assessment based on static, document-centric signals. It answers the question: “Is this a well-formed and relevant title for this document?”
The AI Editor: Semantic Analysis and the Role of BlockBERT
Promising candidates from the initial screening then move to a more rigorous, in-depth interview powered by advanced AI.
The system refines the initial score into the goldmineAdjustedScore. The leak’s description for this attribute is one of the most revealing: “The score for text computed in Goldmine (AlternativeTitlesAnnotator) with additional scoring adjustments applied. Currently includes Blockbert scoring.”
BlockBERT is a specialised, efficient variant of the well-known BERT language model, designed to assess the linguistic merit of each title candidate.
The goldmineBlockbertFactor is a score based on the model’s assessment of semantic coherence, contextual relevance, and natural language.
It can easily distinguish a well-structured title from a keyword-stuffed string. This deep semantic analysis ensures that a title is not just relevant, but also linguistically sound and written for a human.
The Human Element: How NavBoost and Click Signals Shape Title Selection
The final stage of the evaluation is a performance review based on real-world data.
The goldmineNavboostFactor is the definitive proof that user click behaviour directly influences which title is displayed. This connects the entire process to the real-world interactions of billions of users.
NavBoost, a powerful re-ranking system revealed during the U.S. Department of Justice antitrust trial, analyses a vast history of user click data. It looks at nuanced signals of satisfaction, including:
- goodClicks: Clicks followed by a long dwell time, indicating the user found the content valuable.
- badClicks: Clicks that result in a user quickly returning to the SERP (“pogo-sticking”), signalling dissatisfaction.
- lastLongestClicks: An exceptionally strong positive signal, identifying the final result a user clicks and dwells on, suggesting a successful search journey.
The goldmineNavboostFactor integrates this powerful user data directly into the title scoring process.
A title candidate that consistently generates good clicks and wins the lastLongestClicks will be rewarded with a higher score, dramatically increasing its chances of winning the selection competition.
This creates a powerful feedback loop where the SERP itself becomes a live laboratory for title optimisation, with human behaviour as the ultimate judge.
7. Anatomy of a Title Candidate: A Granular Protocol Buffer Analysis
Executive Summary: How Google Grades Your Title
The following section is highly technical, but the core idea is simple.
The Google leak revealed the exact “report card” the search engine uses to score every potential title for your webpage. Instead of getting lost in the technical terms, think of it in terms of these key questions Google is asking:
- Where did this title come from? Google doesn’t just look at the official tag you write. It creates a “pool” of potential titles by also looking at your main headings (), the anchor text of links pointing to your page, and other prominent text. The system knows where each candidate originated.
- Is it a good and relevant title? An internal system gives each title a quality score. It measures how well the title matches the user’s query and the content on the page. It even uses AI to check if the title is well-written and makes sense.
- How do real users react to it? This is critical. A powerful system analyses user clicks. Titles that get “good clicks” (where a user clicks and stays on the page) are rewarded with a higher score. This real-world performance is a massive factor in which title ultimately gets chosen.
- Is the title breaking any rules? The system has specific penalties built in. It flags and demotes titles that are too long and get cut off, are stuffed with repeated words, or use generic, boilerplate text across multiple pages.
The detailed tables that follow are the line-item breakdown of this report card. You don’t need to memorise every attribute, but understanding these four core principles will help you see why the technical details matter and how they influence your SEO strategy.
To understand how to win at modern SEO, you have to understand the technical foundation.
The QualityPreviewRanklabTitle module is a protocol buffer, or “protobuf” – a data serialisation method used all over Google. Its very name tells us that this data is an input for “Ranklab,” Google’s internal machine learning and experimentation platform.
This confirms title selection is a sophisticated, data-driven ranking problem, not a simple set of rules.
The structure is a collection of numerical scores, booleans, and labels, all engineered to be fed into a predictive model.
Of course. Here is a rebuilt table containing only the attributes that are hyper-relevant to the HTML <title> tag and its evaluation.
Title Tag Specific Attributes & Scoring Factors
Note. Any strategic SEO implication is a work of logical inference. Use caution and think critically.
| Attribute Name | Data Type | Strategic SEO Implication |
| Foundational Attributes | ||
text |
String | Provides a clear view of the final candidate text sourced from the <title> tag, including any modifications. |
dataSourceType |
String | Crucial for confirming if the winning title in the SERP was indeed sourced from your “TITLE_TAG”. |
isTruncated |
boolean | A direct signal that a <title> tag exceeding the pixel width limit is identified and likely penalised. |
widthFraction |
number (float) | The critical formatting signal for your <title> tag. A value > 1.0 is a direct input to the scoring model. |
hasSiteInfo |
boolean | Aligns with Google’s public guidance to brand titles concisely. A positive signal when used appropriately in the tag. |
queryMatch |
integer | A fundamental relevance signal showing how many query terms are present in your <title> tag. |
| Source & Scoring | ||
sourceTitleTag |
boolean | The explicit flag confirming the title candidate originated from the HTML <title> element. |
goldmineTitleTagFactor |
number (float) | The single most important attribute. This is the specific score component measuring the intrinsic quality of your chosen <title> tag. |
goldmineIsTitleTag |
number (float) | The numerical version of sourceTitleTag, allowing Google’s model to learn a specific weight or bias for titles originating from the official tag. |
goldminePageScore |
number (float) | Represents the baseline quality assessment of your <title> tag, combining it with other on-page factors. |
goldmineAdjustedScore |
number (float) | The final quality score of your <title> tag after advanced semantic analysis, likely determining if it’s chosen. |
goldmineNavboostFactor |
number (float) | The direct link between historical user engagement (clicks) on your <title> tag and its future selection. |
goldmineBodyFactor |
number (float) | Measures how well your <title> tag represents the page’s content, preventing title-content mismatch. |
| Demotion & Penalty Signals | ||
dupTokens |
integer | A direct, quantifiable measure of keyword stuffing within your <title> tag. A strong negative signal. |
goldmineIsBadTitle |
number (float) | A key demotion feature that can disqualify your <title> tag if it’s deemed low quality. |
goldmineHasBoilerplateInTitle |
number (float) | The direct technical implementation of Google’s public warning against using boilerplate text in <title> tags across your site. |
Common Pitfalls: How Google Identifies and Penalises Bad Titles
Google’s penalties are not just punitive; they are systemic defence mechanisms designed to protect the integrity of the user-behaviour feedback loop that powers NavBoost. Spammy, misleading, or keyword-stuffed titles can generate deceptive clicks, polluting the data NavBoost relies on.
The systems revealed in the leak act as a pre-filter to remove these “pollutants” before they can corrupt the signals.
The documentation reveals a specific data model called DocPropertiesBadTitleInfo, designed to flag and score poorly constructed titles.
This indicates that Google doesn’t just ignore bad titles; it actively identifies and quantifies their poor quality.
This BadTitleInfo score likely acts as a direct negative signal.
I once encountered a clear case where a company’s site was getting no hits. Their home page title was a spammy, 50+ word list of every service and related term imaginable. In the SERPs, Google displayed no title at all for their listing—a clear sign that the system had rejected the title entirely as being fundamentally untrustworthy.

Other attributes directly penalise common SEO anti-patterns.
The goldmineHasBoilerplateInTitle attribute is the technical implementation of Google’s warning against “repeated or boilerplate text” in titles.
The dupTokens attribute provides a simple but effective measure of keyword stuffing by counting repeated words. Furthermore, SERP aesthetics are ranking factors.
The widthFraction and isTruncated attributes are features in the scoring model, meaning a title that is too long is flagged and penalised.
Avoiding these penalties isn’t just about avoiding a demotion; it’s about ensuring your high-quality, user-focused titles are eligible to be fairly judged by the NavBoost system.
Beyond the Title: Deconstructing Google’s Snippet Generation
Just as the RanklabTitle module demystifies title selection, its counterpart, the QualityPreviewRanklabSnippet module, provides a parallel insight into the descriptive text that appears below the title link.
The architecture for snippet selection is a direct parallel to title selection, revealing a unified Google philosophy: “Trust, but verify, through content extraction and user data.“
For years, the conventional wisdom has been to optimise the meta description tag. This module confirms that, much like the title tag, the meta description is merely a suggestion—one of many candidates in a competitive, data-driven selection process. The system, internally codenamed “Muppet,” will pull text from anywhere on your page to form the snippet it believes is most relevant.
The module aggregates features from multiple specialised systems. A key distinction is between queryTermCoverageFeatures and originalQueryTermCoverageFeatures, showing that the system measures relevance against both broad semantic matches and the exact-match terms the user typed.
The presence of radishFeatures is also crucial; analysis of the leak strongly connects the “Radish” system to the generation of Featured Snippets.
Its presence here implies that every standard snippet candidate is also evaluated for its potential to serve as a direct answer.
This reinforces a principle I’ve been teaching for years: you cannot control the SERP, you can only influence it. Snippet optimisation is no longer about writing the perfect meta description in isolation; it’s about structuring your entire page to produce high-quality, relevant snippet candidates.
An Evidence-Based Framework for Title Tag Mastery
“don’t know anyone who has tested title tags more than @shaun_anderson of @Hobo_Web” – Andy Beard, 2021
Over the years, I’ve refined my approach to a set of core principles. I rarely try to be sensational with my titles; my titles are functional. I will often post a functional title and then revisit it after I publish, once I observe how it is performing against competing pages.
I expect my page titles to change over time, for I am usually testing and optimising. Here is an actionable framework that translates this technical analysis into a sophisticated optimisation strategy.
Why Google Rewrites Your Title (And How to Influence It)
It’s now the norm for Google to display a different title than the one you specified. This is not new. Back in 2009, Matt Cutts explained:
”We try to show a relevant, useful title. So there are lots of different heuristics that we can use….So if you have a bad title or a title that we don’t think helps users as much, we can try to find a better title.”
The leak has given us a name for the system responsible: SnippetBrain.
This happens when SnippetBrain believes it can create a title that better matches the user’s query by pulling from your <h1>, body content, or anchor text.
As I’ve seen in my own tests, Google can use everything down to an <h6> tag to form a title if the primary signals are malformed.
As Jennifer Slegg noted, “If Google is rewriting your titles, that is a sign you should work on rewriting those titles”. The best way to minimise unwanted changes is to ensure your <title> tag and your <h1> heading are closely aligned.
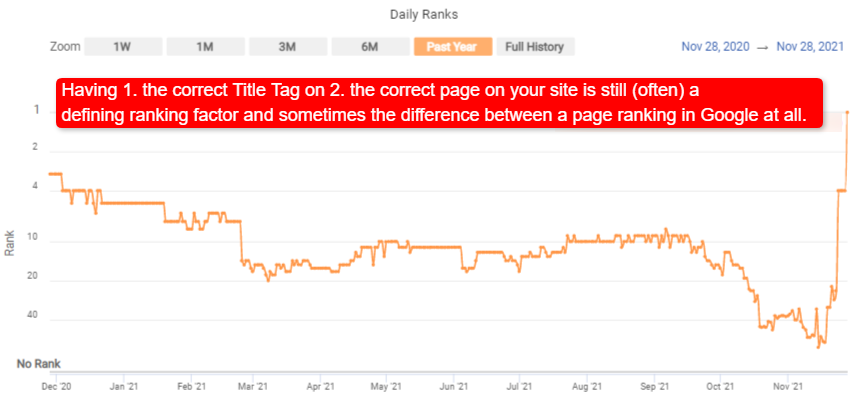
The 12-Word Relevance Rule and the True Word Count Limit
Many years ago, I ran a test to see how many keywords Google would read.
I created a spammy title with 51 words. To my surprise, Google returned the page when I searched for the first and 51st words, proving it had read the entire thing. However, a follow-up test using the intitle: search operator revealed a crucial nuance. Google seemed to stop counting words as part of the “title” for that specific function after the 12th word.
My test using the intitle: search operator revealed a crucial nuance. Google seemed to stop counting words as part of the “title” for that specific function after the 12th word.
At the time Qwerty confirmed an interesting fact about the intitle: site operator in Google.

…..results as expected. But next in the sequence returns the following, unexpected result…..

This led to my long-standing working theory: while Google might read a very long title, only about the first 12 words carry significant weight for relevance scoring.
The leak doesn’t contradict this; it explains it.
My early test was likely an external observation of the distinction between the system’s ability to index long strings versus its process for weighting terms for relevance.
The modern system is more complex, but this historical test provides a fantastic, concrete example of how foundational keyword relevance still matters.
If my title tag is 12 words or fewer, I am fine with that. If it’s too long or truncated, it could send negative signals, so the advice is 1. Aim for under 600px and 2. Only use longer titles (12 words max) when highly relevant to the page.
Actionable Recommendations
- Cultivate Content and Title Alignment for Semantic Coherence: The influence of goldmineBodyFactor and goldmineBlockbertFactor demands deep semantic alignment. Harmonise your <title> tag and your primary <h1> heading. While they don’t need to be identical, their core message must be consistent. Your introductory paragraph should immediately reinforce the promise made in your title.
- Engineer Internal Linking as a Title Reinforcement Mechanism: The existence of sourceOnsiteAnchor as a title source turns internal linking into a direct title optimisation tactic. Implement a disciplined anchor text strategy, using descriptive variations of your ideal title in internal links. Audit and remove generic anchor text like “click here.”
- Optimise for the NavBoost User Engagement Feedback Loop: The goldmineNavboostFactor confirms that titles are judged by their performance with real users. Craft titles that make an accurate promise to attract a click and then fully satisfy the user’s intent, winning the lastLongestClicks. A/B test title formats and monitor click-through rates in Google Search Console to identify what resonates with your audience.
- Adhere to Technical and Formatting Constraints as Ranking Factors: Attributes like isTruncated and dupTokens confirm that technical rules are enforced with scoring penalties.
- Strictly Manage Title Length: My Take: Don’t obsess over the exact character count. Focus on getting your core message and primary keyword phrase within the initial 50-60 character window (approx. 600 pixels). If your title needs to be longer to be descriptive, that’s fine, as Google confirmed in 2021 there is value in longer titles. Just ensure the front-loaded portion makes perfect sense on its own.
- Enforce Uniqueness and Eliminate Repetition: Implement a process to ensure every page has a unique title. Eradicate all boilerplate language from title templates to avoid penalties from the goldmineHasBoilerplateInTitle feature.
- My Take on Separators: While both pipes (|) and dashes (-) are common, analysis of Google’s rewrite behaviour suggests dashes are a ‘safer’ choice. I usually use a dash when writing titles.
- Treat All On-Page Content as a Snippet Candidate: The “Muppet” system will pull text from anywhere on your page. Structure your content with clear, concise, and self-contained sentences that can be easily extracted. Target Featured Snippets (“Radish”) by using question-and-answer formats and clear headings that directly address user queries.
Conclusion: A More Complex, But More Predictable System

If there is one thing I want you to take away from this guide, it is this: your HTML title tag is far more than a simple metadata field. It is a strategic communication tool, a promise you make to a user, and a critical signal of quality and relevance you send to Google.
The increasing complexity of Google’s systems paradoxically makes high-level SEO strategy simpler and more predictable. In the old days, SEO was about finding and exploiting loopholes in a relatively simple, rule-based system. Today, the system is incredibly complex, with multiple interacting machine learning models and feedback loops that are impossible to “trick.” However, the goal of this complex system is singular: to identify and reward content that best satisfies user intent.
The only viable, long-term strategy is to stop trying to game the system and instead focus entirely on the system’s ultimate goal. In the modern era of search, which I see as a “Human-AI Symbiosis,” our job is not to trick algorithms. It is to use our uniquely human skills – our empathy, our strategic thinking, our ability to communicate clearly – to create the signals of quality that Google’s increasingly sophisticated AI systems are designed to find and reward. Crafting a perfect title tag is a small element that reflects a much larger commitment to quality. By mastering it, you are not just optimising a line of code; you are building a more resilient, authoritative, and successful digital presence.
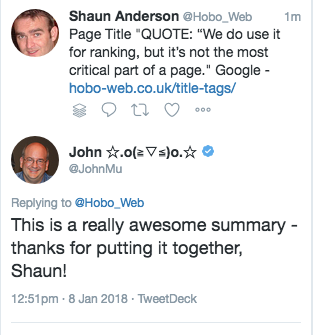
Note: This is a rewrite of a foundational article on the Hobo SEO Blog. The first major version of this article on title tags received a thumbs up from Google’s John Mueller at the time, who said, “This is a really awesome summary (of title tags)“.
Comments are closed.